





Introduction▲
Lorsqu'un programme diverge de son comportement normal, on dit communément qu'il y a un bogue. L'objet de ce tutoriel est d'apprendre à trouver l'origine de ces bogues afin de pouvoir les corriger. Pour ce faire, nous allons tâcher d'observer l'ensemble des variables qui caractérisent le programme au fur et à mesure de son déroulement, afin de détecter l'instant précis où la divergence commence, et donc le morceau de code qui est responsable du comportement erratique observé. Nous allons donc étudier l'ensemble des moyens dont dispose le développeur Java/Java EE pour auditer le déroulement de son programme, et comme un programme bien structuré est beaucoup plus simple à déboguer, nous commencerons par aborder rapidement les bonnes pratiques qui facilitent la vie.
I. Code bien structuré, débogage et maintenance facilitée▲
Un programme astucieusement structuré est bien plus simple à déboguer, car on trouve très vite où se situe le problème, beaucoup plus rapidement que lorsque le programme est très brouillon, de type « pelote de laine ». Dans ce dernier cas, la recherche des bogues s'apparente à la recherche d'une aiguille dans une botte de foin, ce qui va s'avérer frustrant et chronophage. Le temps perdu est alors bien supérieur à celui soi-disant économisé lors de la conception en n'effectuant pas les refactorisations nécessaires en temps voulu. Le paragraphe Un peu d'architecture de mon tutoriel d'introduction à l'écosystème Java vous fournira une bonne introduction aux problématiques d'architecture. Pour illustrer mon propos, voici une liste non exhaustive des avantages apportés par un programme bien conçu :
- il sera facile à maintenir/faire évoluer : si jamais on vous demande d'ajouter une nouvelle fonctionnalité vous n'aurez pas besoin de refactoriser cinquante classes ;
- il sera facile à étudier/comprendre : souvenez-vous que vous n'êtes pas éternel. Un jour quelqu'un d'autre reprendra votre travail et vous détesterez recevoir dix e-mails par jour de sa part parce qu'il ne comprend pas comment vous avez pensé les choses. Accessoirement si vous vous repenchez sur le programme au bout de six mois vous vous autoféliciterez d'avoir fait cet effort, car sinon, c'est le lot de beaucoup d'échecs : on met tout à la corbeille et on réécrit tout de zéro ;
- il sera facile à tester : nous le verrons en partie IV. Les tests sont une obligation dans les gros projets, et un programme mal conçu complique beaucoup le travail des testeurs, et c'est autant de temps perdu ;
- il sera facile à réutiliser : si vous développez un peu toujours dans le même domaine fonctionnel, vous allez vite avoir un certain nombre de problématiques qui reviennent dans beaucoup de programmes. Quoi de plus naturel alors que de séparer le code commun dans un projet à part pour ne pas devoir le réécrire sans cesse ? Encore faut-il qu'il ne soit pas inextricable ;
- il sera généralement beaucoup plus performant. Il n'y a pas vraiment de lien de cause à effet, mais c'est plus lié à un état d'esprit général. Qui cherche à faire un code clair et bien découplé aura généralement beaucoup plus de facilité à cibler les morceaux gourmands en performances et à y apporter un soin spécial.
Un acronyme anglais résume en un monosyllabe tout ce que nous venons de dire : KISS (Keep It Simple, Stupid and Short), qui se traduit par « Faites simple, bête et court ». Chaque fois que vous envisagerez de mettre en place un mécanisme très élaboré à base de classes abstraites et de génériques, ayez-le à l'esprit et demandez-vous si le gain apporté par ce nouveau mécanisme va vraiment compenser la lourde perte de lisibilité/maintenabilité/évolutivité du code ;).
II. Débogage en phase de développement▲
Le Débogage en phase de développement est bien plus simple qu'en phase de production, car vous pouvez agir à votre guise sur le programme, et l'ausculter plus facilement. Attention tout de même, un programme exempt de bogues en développement reste susceptible de présenter des anomalies en production qui reste le seul vrai test.
II-A. L'affichage de valeurs dans la console▲
C'est de loin la méthode la plus simple et la plus accessible aux débutants, tant que l'on reste dans le cadre de petits programmes peu complexes ou qu'il est impossible de faire autrement. À divers endroits dans le code source, on va insérer des 'system.out.println("ma_variable="+ma_variable.toString())', puis lors de l'exécution du programme on va regarder la console et voir défiler les valeurs des variables.
Cette méthode a plusieurs gros inconvénients, le plus gênant étant que pour activer/désactiver ces traces en console, il faut impérativement modifier le code source et recompiler. Parmi les autres inconvénients, il y a le fait que le média de sortie est par défaut la console (plutôt qu'un fichier), et le fait que les appels toString() ainsi que les appels println() ne sont pas neutres en matière de performance et peuvent ralentir énormément le programme dans certains cas.
Par ailleurs si vous développez une bibliothèque dont quelqu'un d'autre va se resservir plus tard pour développer une nouvelle brique fonctionnelle, il n'aura pas forcément envie d'avoir sa console polluée d'affichages, et d'un autre côté, il peut tout de même avoir envie de savoir ce qui se passe. Enfin, niveau visibilité, un code bourré de sorties console n'est pas génial. Cette méthode est donc à réserver aux petits projets très simples, et aux cas où l'on ne peut pas faire autrement.
II-B. Utilisation d'outils de journalisation (logging)▲
Le principe est le même que lors de l'utilisation de l'affichage en console, mais on va utiliser un outil dédié qui va permettre d'affiner le niveau d'information que l'on veut obtenir sans avoir besoin de modifier le programme, et de choisir où ces informations seront enregistrées. Les outils de logs étant plus appropriés pour observer un programme en production, nous reviendrons plus en détail sur le sujet en partie III.
II-C. Utilisation du mode debug de votre IDE▲
Le principe du mode debug est de faire avancer le programme au pas-à-pas afin de pouvoir observer chacun de ses états successifs. Il y a plusieurs IDE qui proposent un mode debug, dans le cadre de ce tutoriel nous nous restreindrons à présenter le mode debug d'Eclipse, qui est l'IDE le plus répandu. Nous utiliserons l'interface par défaut, mais nous encourageons vivement le lecteur à réorganiser son interface d'une manière plus ergonomique.
Les captures d'écran qui illustrent ce tutoriel ont été prises avec une version standard d'Eclipse. Le projet qui tourne à l'intérieur est l'un des exemples de démonstration de spring-security.
II-C-1. Lancement d'un programme en mode debug.▲
Pour lancer un programme en mode debug, il y a plusieurs solutions, via un raccourci clavier ou via le menu, mais pour l'heure, faites un simple clic droit sur votre projet, survolez le menu déroulant « debug » dans le menu contextuel, puis suivant qu'il s'agisse d'une application Java EE ou non, lancez le débogage sur le serveur ou en tant qu'application Java. Eclipse devrait vous proposer d'afficher la vue de debug, ce que nous vous conseillons d'accepter en cochant la case « toujours… ».
Pour ceux qui font du Java EE :
Si le programme que vous souhaitez déboguer est déployé sur un serveur d'applications indépendant (éventuellement situé sur un autre ordinateur),
vous pouvez lancer le débogage en mode remote, comme l'illustre la capture d'écran suivante. Pour afficher ce menu, repérez l'icône représentant un insecte
dans la barre d'outils supérieure et cliquez sur la petite flèche à sa droite pour faire apparaitre un menu déroulant dans lequel vous cliquerez sur « debug
configurations ». À noter que pour que cela fonctionne, il faut que le serveur d'applications où est déployée l'application soit configuré de manière à accepter
le débogage à distance. Pour aller plus loin…

II-C-2. Exécution en pas-à-pas▲
Le but principal de l'exécution en mode debug, c'est de pouvoir avancer en pas-à-pas dans le déroulement du programme. Pour cela nous allons placer un point d'arrêt à l'endroit qui nous intéresse afin de signaler au débogueur de s'arrêter lorsque le programme passe dans cette partie du code. Pour ce faire, double-cliquez dans la marge au début de la ligne de code où vous souhaitez démarrer le mode pas-à-pas. Un point bleu apparaît à cet endroit (là où pointe la flèche dans l'image qui suit), et le point d'arrêt est visible dans la liste des points d'arrêt de l'onglet « breakpoints » sur lequel nous reviendrons au III.C.3.
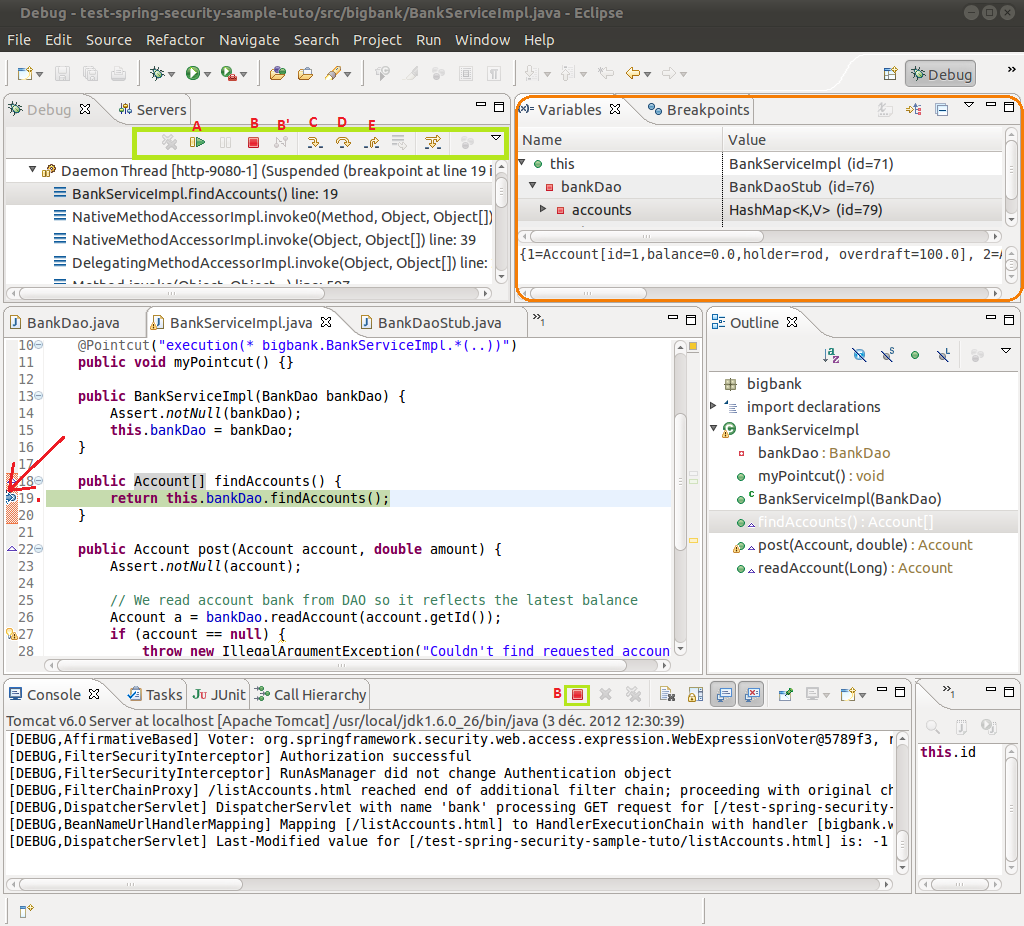
Il y a beaucoup à dire sur cette image. Tout d'abord, le cadre que nous avons entouré en orange permet de connaître les valeurs de l'ensemble des variables à chaque étape du pas-à-pas (et éventuellement de les modifier via un clic droit). Ensuite la barre d'outils que nous avons entourée d'un cadre vert est celle qui va nous permettre de contrôler la progression du mode pas-à-pas. Nous allons maintenant détailler l'utilité de chaque bouton d'après la lettre que nous lui avons associée :
- ce bouton « play » permet de sortir du mode pas-à-pas, il indique au programme de se poursuivre normalement jusqu'à ce qu'il rencontre le prochain point d'arrêt ;
- ce bouton « arrêt », qui est reporté dans la barre d'outils du bas sert à stopper le serveur d'Éclipse. Si le programme débogué est déployé sur un serveur d'applications indépendant, il sera grisé et c'est le bouton B' « disconnect » qui apparaîtra ;
- ce bouton « rentrer » permet de continuer le pas-à-pas dans la sous-fonction qui va être appelée sur cette ligne s'il y en a une ;
- ce bouton « sauter » permet de sauter à la ligne suivante dans l'exécution de la méthode en cours ;
- ce bouton « remonter » permet de terminer l'exécution de la méthode actuelle et de poursuivre le pas-à-pas dans la méthode appelante.
Il est même possible de placer des points d'arrêt dans des bibliothèques. Cependant c'est assez complexe, nous ne le détaillerons donc pas ici.
Sur cette partie du debug, voir aussi DébogueurÉclipse
II-C-3. Points d'arrêt conditionnels▲
Dans certains cas, on peut souhaiter que le programme ne s'arrête sur un point d'arrêt que si une condition prédéfinie est remplie :
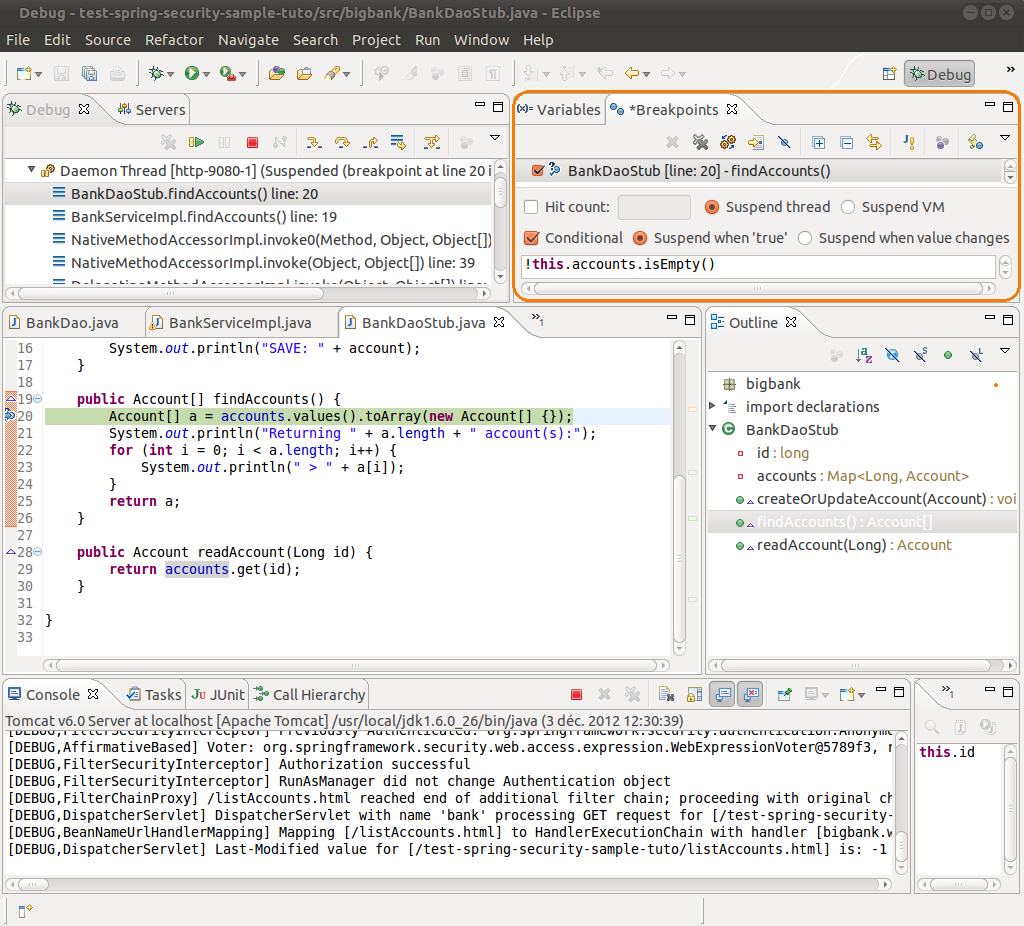
La capture d'écran parle d'elle-même. Comme vous pouvez le voir, les possibilités sont multiples. Bien sûr l'autocomplétion fonctionne dans le cadre d'écriture des conditions, ce qui est très pratique.
II-C-4. Tester des morceaux de code pendant le pas-à-pas▲
Un certain nombre de vues permettant d'aider le debug, affichez-les via le menu « Fenêtre », « Afficher la vue », « Nom de la vue » (ou cliquez sur « Autres… » pour les rechercher si elles ne sont pas dans la liste par défaut), puis réorganisez l'interface pour les afficher à un endroit commode.
II-C-4-a. Via des expressions.▲
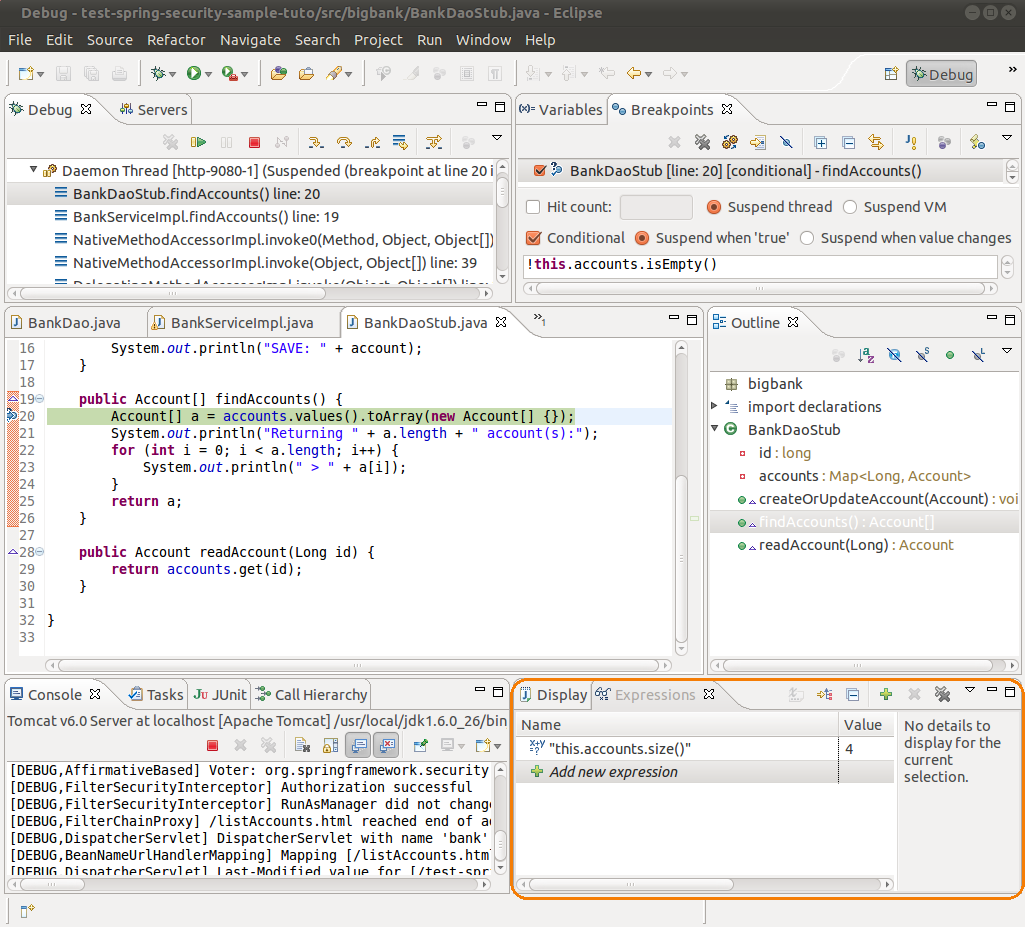
Comme l'illustre la capture d'écran, cette vue vous permettra de renseigner des expressions qui seront ensuite réévaluées à chaque fois que vous avancerez d'un pas dans le débogage.
II-C-4-b. Via la vue display.▲
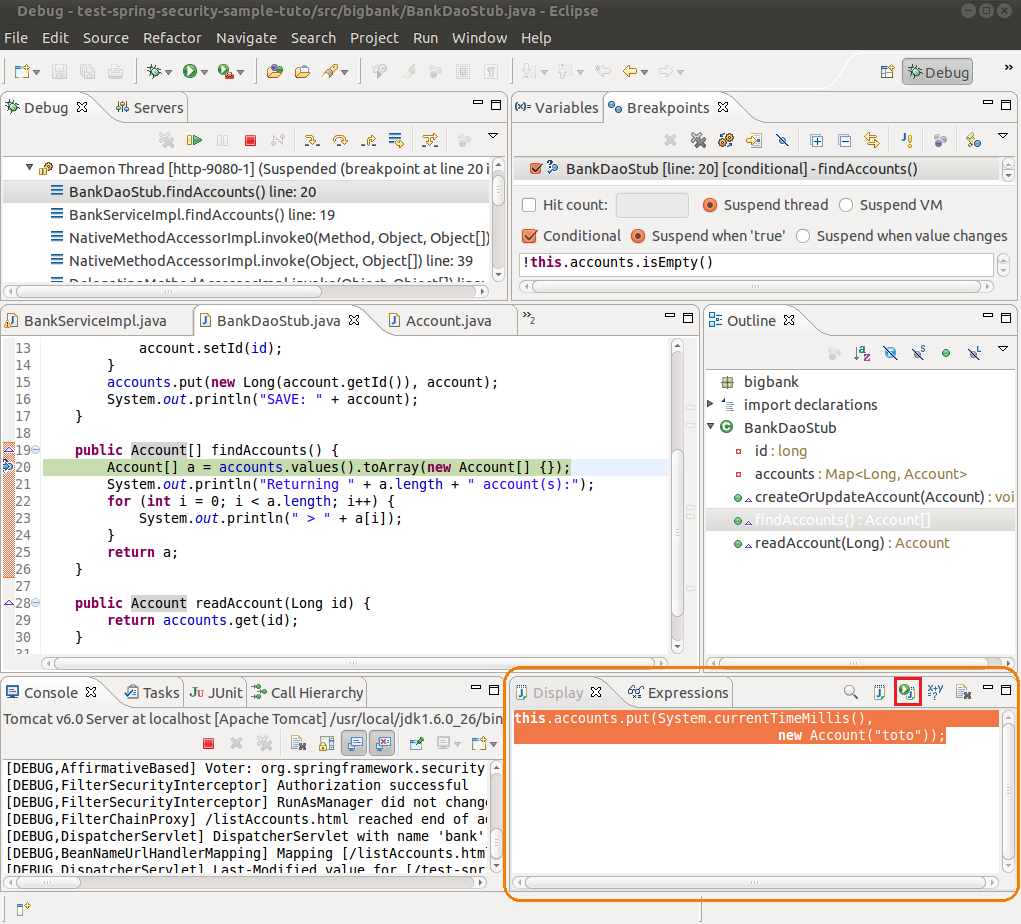
Très pratique, la vue display (où l'autocomplétion fonctionne également) permet d'exécuter du code pour altérer le comportement du programme d'une manière un peu plus aboutie que la simple modification de ses variables. Par exemple sur la capture d'écran nous ajoutons un objet dans une map, objet qui sera conservé dans la suite de l'exécution du programme. Tapez votre commande, sélectionnez-la, et cliquez sur le bouton « play » que nous avons encadré en rouge pour l'exécuter.
III. Débogage en phase de production▲
En phase de production il est plus compliqué de rechercher la source d'un problème, le programme est activement exploité sur un site distant, dans le meilleur des cas vous avez accès SSH au serveur où il est déployé, mais dans beaucoup de cas de figure il vous faut vous contenter des informations que l'on veut bien vous donner. La manière de procéder est donc différente : alors qu'en environnement de développement vous aviez toute latitude pour analyser le comportement du programme à chaque instant, ici vous allez devoir reconstituer ce qui s'est passé en analysant les traces.
III-A. Via l'analyse des logs▲
C'est le moment d'entrer plus en détail sur la journalisation, que nous n'avions que brièvement évoqué au II.B. Le principe est très simple : à tous les endroits du code où vous vous dites qu'il serait intéressant de savoir plus tard ce qui s'est passé, vous allez effectuer un appel sur votre API de logging en définissant le niveau d'importance de l'information. Par la suite, vous allez modifier le fichier de configuration de votre bibliothèque de journalisation pour définir précisément quelles sont les informations que vous voulez récupérer (par exemple en fonction de leur niveau d'importance et du nom de paquet) et où vous souhaitez les écrire.
Rappel : la journalisation s'appuie sur une API qui regroupe l'ensemble des classes que vous aurez besoin d'appeler depuis votre programme Java, mais cette API se borne à un rôle d'interface et la journalisation effective est réalisée par une autre bibliothèque. Vous entendrez par exemple parler de commons-logging/log4j (plutôt dans le cadre de projets anciens), et de SLF4J/LogBack (combo gagnant pour les projets récents). L'un des gros avantages apportés par Logback est le fait qu'il peut recharger automatiquement son fichier de configuration à intervalles réguliers, ce qui évite de devoir redémarrer le serveur à chaque modification et s'avère du coup très utile en environnement de production. Si vous utilisez Log4J il est possible de parvenir à un résultat équivalent via un Listener chargé d'effectuer la recharge à chaud.
La plupart des outils de journalisation définissent six niveaux :
- TRACE : niveau qui affiche le plus d'information. On peut par exemple mettre une trace à chaque entrée et sortie de méthode, et dans chaque boucle itérative. Beaucoup de développeurs jugent qu'il pollue le code et ne l'utilisent pas ;
- DEBUG : pour afficher les informations dont on s'attend à avoir besoin si un problème survient ;
- INFO : pour afficher les informations dont on juge qu'elles peuvent être intéressantes pour la personne chargée de monitorer le programme, mais sans revêtir de caractère alarmant ;
- WARN : pour afficher des informations sur des problèmes qui à eux seuls ne suffisent pas à faire planter le programme, mais traduisent un comportement anormal :
- ERROR : lorsque le programme rencontre un problème qui empêche son fonctionnement ;
- FATAL : lorsqu'une erreur va probablement induire un plantage complet du programme.
Certains outils permettent même de définir des niveaux personnalisés, cependant il y a déjà amplement de quoi faire avec ces six-là. Au niveau du fichier de configuration, vous pourrez par exemple définir que tous les messages de niveau INFO ou plus doivent être enregistrés dans un fichier horodaté journalier suivant un pattern de type monappli-201YMMJJ.log, tandis que les informations de niveau TRACE et plus iront dans un fichier numéroté de maximum 200 MO suivant un pattern de type monappli-debug-N.log avec N compris entre 1 et 10, et effacement automatique du plus ancien. Ce type de configuration vous garantit de conserver à part les informations les plus importantes sur le déroulement du programme, et de pouvoir accéder aux logs détaillés de l'histoire récente de l'application.
Attention, les traces peuvent avoir un coût non négligeable en matière d'utilisation de ressources matérielles, il est donc recommandé de se limiter au minimum vital, en se réservant la possibilité de modifier le fichier de configuration à chaud pour activer les traces correspondant au problème du moment.
III-B. Via un framework d'audit▲
Les frameworks d'audit permettent de surveiller le déroulement normal d'une application. Ils sont souvent associés à la programmation orientée aspect (AOP) car ils effectuent une tâche relativement transverse avec une logique indépendante du code source. Ils peuvent par exemple être paramétrés au moyen d'annotations ou de fichiers XML. Nous ne nous attarderons pas sur la question, car ils ne sont pas l'outil le plus utile pour le débogage, mais il était néanmoins intéressant de les mentionner, car ils peuvent apporter des informations complémentaires.
Dans le même ordre d'idées, il existe des outils comme Yourkit qui permettent de surveiller les performances du système et de la JVM.
III-C. Via des JSP dédiées (Java EE seulement)▲
Dans le cadre d'une application Java EE, il peut être intéressant de disposer d'une ou plusieurs JSP dédiées au diagnostic (que vous pouvez par exemple protéger via une basic-auth). Voici une liste non exhaustive de cas d'usage :
- pour afficher des renseignements de base comme la date du dernier redéploiement et quelques statistiques pertinentes sur la santé de votre application ;
- si votre application dépend de web-services tiers, vous aurez besoin de savoir si l'interrogation de ces web-services se déroule comme prévu. Par exemple il est possible que le web-service soit accessible depuis votre poste de développement, mais que pour une raison quelconque (réseau, pare-feu, règle Apache) il soit bloqué du point de vue de votre application, ou encore, il est possible que votre application ne vous renvoie pas les données que vous souhaitez obtenir, et que vous souhaitiez savoir si la faute doit être imputée au web-service ou aux traitements internes à votre application, auquel cas une petite JSP renvoyant les résultats bruts de l'interrogation du web-service pourrait s'avérer un précieux allié au diagnostic ;
- par ailleurs, le gros avantage d'une JSP, c'est que toute modification à chaud est prise en compte instantanément par le serveur sans qu'il soit nécessaire de le redémarrer… Ce qui peut s'avérer très utile pour tester un petit bout de code à des fins de débogage.
III-D. Robustesse : pertinence des informations de debug▲
Par robustesse, on ne se réfère pas uniquement la capacité d'un logiciel à résister aux erreurs, mais aussi à sa capacité à fournir des informations détaillées, utiles et pertinentes !
Une des bonnes pratiques est le système de trace/log. On considère que les logs sont uniquement des informations fonctionnelles et les traces des informations techniques (ex. : une stacktrace). On peut alors utiliser des identifiants de transaction que l'on conservera dans les logs et dans les traces pour surveiller l'activité du logiciel durant une transaction particulière. Ce système d'identification de transaction permet de limiter les données propagées et ajoutées à chaque couche. Exemple :
22/12/2012 13:57:01 INFO [00001] Connexion de l'utilisateur DUPONT
22/12/2012 13:57:01 INFO [00002] Connexion de l'utilisateur DUFFOUR
22/12/2012 13:57:01 INFO [00001] Ouverture du document titi.txt
22/12/2012 13:57:01 INFO [00002] Ouverture du document titi.txt
22/12/2012 13:57:01 INFO [00002] Échec de la pause du verrou.Il suffit de recouper les informations d'une même transaction pour comprendre que DUFFOUR a essayé d'ouvrir le fichier titi.txt, mais qu'il n'a pas pu obtenir le verrou.
La robustesse ne concerne pas que les logs, mais également les informations que le logiciel va pouvoir afficher à l'utilisateur. Dans l'exemple évoqué ci-dessus voici, par degrés de robustesse croissants ce que pourrait afficher le programme :
- le logiciel a rencontré une erreur fatale ;
- le logiciel n'a pas pu ouvrir le document ;
- le document est verrouillé ;
- le document est verrouillé par un autre utilisateur ;
- le document est verrouillé par DUPONT.
IV. Outils pour faciliter la détection des régressions▲
IV-A. Tests unitaires et d'intégration▲
Admettons que vous ayez écrit un programme qui comprenne une dizaine de classes, aboutissant à une trentaine de possibilités d'usage fonctionnel. Supposons que vous décidiez d'en refactoriser une partie pour ajouter une nouvelle fonctionnalité. Comment être certain alors que votre changement n'a pas induit de régression à moins de retester manuellement tous les cas d'utilisation envisageables ? Ce qui peut s'avérer de plus en plus gourmand en temps au fur et à mesure du développement. Supposons que vous suiviez une méthode de développement dans laquelle il faut livrer un prototype fonctionnel à chaque fin de semaine. S'il vous faut plus d'une semaine pour refaire tous les tests manuellement vous avez un très gros problème. Vous pouvez alors décider d'intégrer un plus grand volume de fonctionnalités avant de refaire les tests, ce qui accroîtra mathématiquement les risques de bogues. Finalement vous serez contraint de faire ce que tout le monde fait : utiliser des tests de non-régression partiellement ou totalement automatisés. Mais attention, tout programme ne se prête pas forcément à des tests. Ça dépend de comment il a été conçu. Dans le cas de certains programmes particulièrement mal ficelés qui mêlent du code métier, du code de présentation et du code de service ou qui font des appels via des méthodes statiques entre singletons, il n'y aura pas d'autre choix que de réécrire une bonne partie des classes juste pour les rendre testables. D'où l'intérêt d'avoir la problématique des tests en tête dès le moment où l'on conçoit l'architecture du code.
Nous allons distinguer deux types de tests :
- les tests d'intégration sont des tests qui permettent d'analyser les entrées-sorties du programme qui est alors vu comme une boite noire (on se moque de ce qu'il contient pourvu que lorsqu'on envoie certaines données, la réponse corresponde à ce qui est attendu). Leur très gros avantage est qu'ils n'ont pas besoin d'évoluer avec le code : tant que l'on continue de garantir la rétrocompatibilité du programme, les évolutions de celui-ci ne doivent pas casser les tests (bien sûr vous devriez avoir de temps en temps des évolutions qui modifient certains tests, mais rarement un grand nombre de tests d'un coup). Dans le cadre d'une application web, il est courant que sélénium soit utilisé ;
- les tests unitaires sont destinés à tester une seule et unique classe. Cela signifie que si la classe en question fait des appels en base de données, on va utiliser un mock (une classe qui simule le comportement de la classe d'accès à la base de données) afin d'effectuer le test en environnement neutre. Cela implique que les accès en base de données ne sont pas écrits directement dans la classe testée, mais délégués à une classe qui ne fait que ça, et qui est injectée dans la classe lorsqu'elle est construite. C'est ici qu'on voit l'importance d'avoir bien pensé l'architecture globale du programme et le découplage des différentes couches.
À partir du moment où vous avez un test unitaire pour chacune de vos classes et/ou un test d'intégration pour chacune de vos fonctionnalités, vous pouvez dormir relativement tranquillement : si une modification de code introduit une régression importante, elle sera quasi systématiquement détectée lors de l'exécution des tests. Un élément important est aussi qu'il doit être facile de relier un groupe de tests à une exigence/fonctionnalité/etc., afin de connaître le scope fonctionnel qui est KO et de mieux prioriser/cibler les corrections.
La limite des tests est qu'ils ne peuvent épuiser l'ensemble des possibilités du programme. À chaque fois c'est juste un cas d'école qui est testé, et vous pouvez passer à côté de problèmes non prévus.
Pour ceux qui souhaiteraient creuser un petit peu la question, la documentation sur Developpez.com est très riche sur la question. Vous pouvez également jeter un coup d'œil à tout ce qui est relatif aux outils de build automatisé. Mentionnons enfin qu'il existe des outils qui permettent d'analyser quelles sont les parties de votre code qui sont bien testées et celles qui mériteraient de l'être mieux, citons par exemple Cobertura et Clover.
Certains développeurs utilisent les tests pour certifier la conformité du programme au cahier des charges. Si c'est votre cas, nous vous déconseillons d'écrire les tests après avoir écrit le code qu'ils doivent tester. En effet votre impartialité serait alors biaisée et vous auriez tendance à écrire des tests qui passent dans votre compréhension du cahier des charges. Il est bien plus intéressant de commencer par écrire les tests, de s'assurer qu'ils compilent, mais ne passent pas (normal, vous n'avez encore rien écrit, et puis dans le cas contraire, c'est soit que le test a un problème, soit que la fonctionnalité était en fait déjà couverte par le code existant, et que vous n'avez donc rien à faire) et de vous astreindre à ne commencer à coder qu'après. Pour programmer ludiquement, vous pouvez écrire les tests pour vos collègues et leur demander d'en faire de même pour vous. Ces pratiques, qui rentrent dans le domaine du TDD (Test Driven Developement ou développement guidé par les tests) permettent d'être certain de respecter le cahier des charges sans être biaisé. Et puis l'avantage est que lorsque le développement s'achève, les tests sont déjà là, pas de risque de les oublier ou de les remettre aux prochaines calendes grecques à cause de la deadline qui arrive.
IV-B. Outils d'analyse automatique de code▲
De nombreux outils d'analyse du code existent. Ils parcourent le code source automatiquement, repèrent les redondances, les situations connues comme problématiques et tous les endroits où les bonnes pratiques ne sont pas respectées. La plupart peuvent être utilisés en tant que plugins Maven ou indépendamment. Il existe des solutions tout-en-un comme Sonar, qui est capable de récupérer automatiquement le code dans un dépôt subversion, de l'analyser, et de présenter des rapports de synthèse graphique dans un navigateur web. Lorsqu'une société fait réaliser un logiciel au forfait et qu'elle en achète le code source, vous avez 90 % de chances qu'elle s'appuie sur l'un de ces outils pour juger de la qualité du code livré.
IV-C. Intégration continue▲
L'intégration continue fait un pas de plus dans l'automatisation des tests. Généralement couplé à un outil de build comme Ant ou Maven, l'outil d'intégration continue va surveiller le dépôt où est centralisé le code source et recompiler automatiquement le projet à chaque changement. Il enverra optionnellement une notification à l'outil d'analyse du code pour qu'il prenne en compte les derniers changements. Selon la manière dont l'outil de build est configuré, il pourra lancer automatiquement l'ensemble des tests unitaires (comportement par défaut de Maven) et d'intégration (configurable via des plugins dédiés), et enverra automatiquement des e-mails aux développeurs en cas de problème. De manière optionnelle, si le logiciel fait office de serveur (par exemple s'il s'agit d'une appli Java EE), un plugin peut permettre de la redéployer automatiquement, de façon à avoir une version démo intégrant les toutes dernières fonctionnalités disponibles en permanence.
Conclusion▲
Comme nous l'avons vu, le mieux est de ne pas avoir de bogue en effectuant un travail en amont afin d'avoir un code clair, simple, bien structuré (KISSS), et en réalisant suffisamment de tests unitaires et d'intégration afin d'éliminer au maximum la probabilité d'introduire des régressions. Pour les bogues qui passent tout de même au travers des mailles du filet, la manière la plus simple de les corriger est de reproduire le problème dans son environnement de développement et de scruter le déroulement du programme au pas-à-pas afin de voir où le bât blesse. Si le problème n'est pas reproductible, l'analyse des traces logicielles doit permettre de remonter à sa source.
Remerciements▲
Au moment de publier enfin cet article, je voudrais remercier bpy1401, Gueritarish, ra77 et thierryler pour leurs conseils, keulkeul et Nemek pour leur relecture technique et leurs encouragements, ainsi que zoom61 et ClaudeLELOUP pour leur relecture orthographique et leurs conseils, et enfin djibril pour son aide dans l'utilisation des outils de rédaction.